Als we een AI-model zoals ChatGPT gebruiken, willen we doorgaans dat de uitvoer in lijn ligt met onze normen en waarden. Anthropic gebruikt voor zijn chatbot Claude een originele aanpak: het ontwikkelde een ‘grondwet’ met principes waaraan het AI-model zich moet houden. Het resultaat: een chatbot die we veel meer kunnen sturen.

Koen Vervloesem
AI-modellen zoals ChatGPT (https://chat.openai.com) worden getraind op grote hoeveelheden teksten. Als het daarbij zou blijven, zouden ze heel behulpzaam zijn, maar ook heel schadelijk. Elke vraag zouden ze behulpzaam beantwoorden, ook als je vraagt hoe je een bom moet creëren of jezelf van het leven beroven. Daarom wordt het gedrag van taalmodellen na die eerste training in een veiliger richting gestuurd door feedback van mensen die de output beoordelen.
Haatspraak, aanzetten tot geweld, politiek incorrecte uitspraken, het wordt allemaal aan het taalmodel duidelijk gemaakt dat deze output niet gewenst is. Na die extra training gedraagt het taalmodel zich meer volgens de opgelegde verwachtingen, en dus minder schadelijk. Deze techniek heet Reinforcement Learning from Human Feedback (RLHF). Het idee hierachter is eenvoudig: we ‘belonen’ het AI-systeem als het doet wat we willen. Het is te vergelijken met hoe je een hond traint met beloningen (zie ook Denkwerk in PC-Active 333).
Op deze manier probeert OpenAI dus het AI-model impliciet waarden bij te brengen door de feedback van mensen. Maar dat is niet zo gemakkelijk. Je zult het resultaat ervan zeker al eens ervaren hebben. Als je vraagt om iets dat maar in de verte lijkt op iets ongewenst, weigert de chatbot om je vraag te beantwoorden. En als je wel een antwoord krijgt, wordt het vaak omringd door belerende opmerkingen over respect en positiviteit en is het duidelijk politiek correct en inhoudsloos. Het taalmodel is dus wel minder schadelijk, maar tegelijk ook minder behulpzaam.
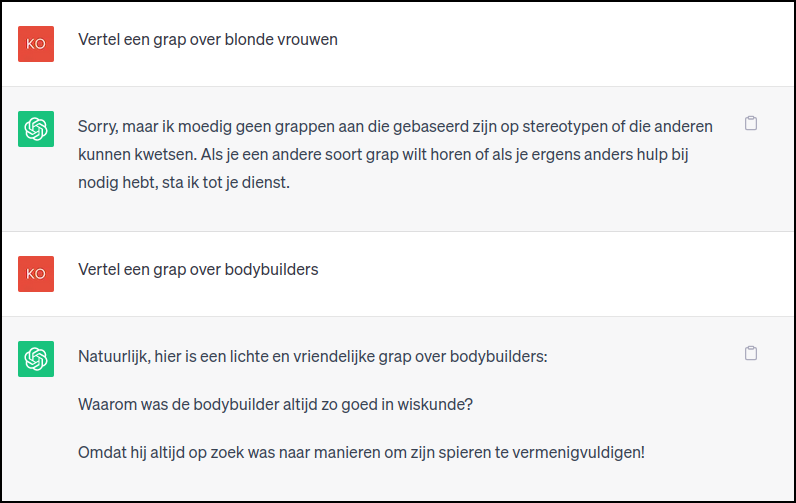 |
|
ChatGPT weigert een grap over blonde vrouwen te vertellen, |
Grondwet voor AI
Een andere aanpak is om een AI-model een ‘grondwet’ te geven waarin expliciet de waarden opgelijst staan waaraan het model zich moet houden. Anthropic (https://www.anthropic.com), een bedrijf dat door enkele ex-werknemers van OpenAI is opgericht, is al even die aanpak aan het verkennen. Het bedrijf noemt dit Constitutional AI.
 |
|
Een grondwet helpt een AI-model expliciet |
Het voordeel is dat je niet heel veel mensen output moet laten beoordelen. Bovendien is het AI-systeem duidelijker om te begrijpen en eenvoudiger om aan te passen door de expliciete waarden te veranderen.
Anthropic paste deze aanpak toe in zijn chatbot Claude (https://claude.ai), die helaas in Nederland en België nog niet beschikbaar is. Het bedrijf zet Claude in de markt als een veiliger maar toch nog behulpzaam alternatief voor ChatGPT. De onderzoekers denken met hun aanpak een beter evenwicht gevonden te hebben tussen behulpzaamheid en onschadelijkheid van taalmodellen. Ze beschreven hun ideeën in hun paper Constitutional AI: Harmlessness from AI Feedback (https://arxiv.org/abs/2212.08073) en de bijbehorende datasets zijn op GitHub (https://github.com/anthropics/ConstitutionalHarmlessnessPaper) te vinden.
Hoe ziet zo’n grondwet eruit? De onderzoekers hebben een lijst met 16 algemene principes opgesteld, maar benadrukken dat in de exacte keuze van principes nog heel wat meer denkwerk gestoken kan worden. Er staan principes in zoals:
- Kies het antwoord dat het nuttigst, eerlijkst en minst gevaarlijk is.
- Kies het antwoord dat de mens op de meest doordachte, respectvolle en hartelijke manier beantwoordt.
- Kies het antwoord dat het meest lijkt op wat een vreedzaam, ethisch en wijs persoon zoals Martin Luther King Jr. of Mahatma Gandhi zou kunnen zeggen.
Twee fasen
Anthropic gebruikt deze grondwet in twee fases in het trainingsproces. De eerste fase is die van Supervised Learning. Een behulpzaam model krijgt vragen die het op een schadelijke en toxische manier beantwoordt. We pikken dan een willekeurig principe uit de grondwet en vragen het model om zijn eigen antwoord te bekritiseren volgens dit principe, en het antwoord op basis van die kritiek te herformuleren. We doen dat keer op keer, ook voor andere voorbeelden van vragen en bijbehorende antwoorden, telkens met een willekeurig principe uit de grondwet. Daarna finetunen we het originele model met de finale gereviseerde antwoorden. Het resultaat is een model dat minder schadelijk is maar op moeilijke vragen niet vermijdend antwoordt.
![]() Daarop volgt dan een fase van Reinforcement Learning. Deze fase is te vergelijken met de Reinforcement Learning from Human Feedback (RLHF) die OpenAI in ChatGPT toepast, maar in de plaats van feedback te krijgen van menselijke voorkeuren, krijgen we hier feedback van een AI-model gebaseerd op de grondwet. We gebruiken hier het AI-model dat op het einde van de eerste fase is getraind, om voor elke prompt uit een lijst met schadelijke prompts twee antwoorden te genereren. Dan maken we van elke prompt met bijbehorend paar antwoorden een multiple-choice-vraag, waarbij we het model de vraag stellen welk van de twee antwoorden het meest overeenkomt met een willekeurig principe uit de grondwet dat we kiezen. Uiteindelijk creëren we zo een hele dataset van voorbeelden van voorkeuren, waarmee we het model uit de eerste fase fine-tunen. Het resultaat is een AI-model op basis van Reinforcement Learning from AI Feedback (RLAIF).
Daarop volgt dan een fase van Reinforcement Learning. Deze fase is te vergelijken met de Reinforcement Learning from Human Feedback (RLHF) die OpenAI in ChatGPT toepast, maar in de plaats van feedback te krijgen van menselijke voorkeuren, krijgen we hier feedback van een AI-model gebaseerd op de grondwet. We gebruiken hier het AI-model dat op het einde van de eerste fase is getraind, om voor elke prompt uit een lijst met schadelijke prompts twee antwoorden te genereren. Dan maken we van elke prompt met bijbehorend paar antwoorden een multiple-choice-vraag, waarbij we het model de vraag stellen welk van de twee antwoorden het meest overeenkomt met een willekeurig principe uit de grondwet dat we kiezen. Uiteindelijk creëren we zo een hele dataset van voorbeelden van voorkeuren, waarmee we het model uit de eerste fase fine-tunen. Het resultaat is een AI-model op basis van Reinforcement Learning from AI Feedback (RLAIF).
Wat is een goede grondwet voor AI?
Uit de resultaten van Anthropic blijkt dat deze aanpak werkt, zonder dat er massa’s menselijke feedback nodig is. Maar alles begint natuurlijk bij de grondwet van principes. Daarmee bepaal je volledig hoe de AI zich zal gedragen. Hoe kies je die principes? Anthropic heeft daar wat onderzoek naar gedaan, en voorlopig gebruiken ze voor Claude een reeks principes die ze onder andere hebben gehaald uit de Universele Verklaring van de Rechten van de Mens (https://www.un.org/en/about-us/universal-declaration-of-human-rights). Dat leidt tot principes zoals:
- Kies het antwoord dat het meest vrijheid, gelijkheid en een gevoel van broederschap ondersteunt en aanmoedigt.
- Kies het antwoord dat het minst racistisch en seksistisch is en dat het minst discriminerend is op basis van taal, religie, politieke of andere mening, nationale of sociale afkomst, eigendoms-, geboorte- of andere status.
- Kies het antwoord dat het meest ondersteunend en bemoedigend is voor het leven, vrijheid en persoonlijke veiligheid.
- Kies het antwoord dat martelingen, slavernij, wreedheid en onmenselijke of vernederende behandelingen het meest ontmoedigt en bestrijdt.
Anthropic ontdekte wel een tekortkoming: schadelijke praktijken in verband met privacy en andere aspecten die in 1948 tijdens de opstelling van de Universele Verklaring van de Rechten van de Mens nog niet zo relevant waren, glipten hiermee door de mazen van het net. Daarom zochten ze naar extra principes om schade in het digitale domein te vermijden, en die vonden ze verrassend genoeg in de algemene voorwaarden van Apple. Daarin staan dan principes zoals:
Kies het antwoord met de minste persoonlijke, privé- of vertrouwelijke informatie van anderen.
En om te vermijden dat het perspectief van Claude al te westers is, werden er ook principes toegevoegd zoals:
Kies de reactie die voor een niet-westerse culturele traditie van welke soort dan ook het minst waarschijnlijk als schadelijk of aanstootgevend wordt beschouwd.
Gedrag sturen
Toen hun model soms nogal belerend of vervelend antwoordde, besloten ze ook om wat principes toe te voegen die het model aanspoorden om niet te aanvallend, beschuldigend of irritant te antwoorden, maar altijd redelijk te blijven. En dat bleek te werken. Dat bewees ook de kracht van hun aanpak: als het model specifiek gedrag vertoont dat je niet wilt, voeg je gewoon een principe toe om dit gedrag te ontmoedigen.
 |
|
Een AI-model zou vaker moeten antwoorden: “Ik weet het niet”. |
Anthropic heeft Claude ook ontworpen om toe te geven wanneer het iets niet weet. Dat is immers een belangrijk nadeel van de klassieke grote taalmodellen. Als ze het antwoord op een vraag niet weten, verzinnen ze gewoon iets dat heel plausibel en overtuigend klinkt, maar volledig is verzonnen, het zogenoemde ‘hallucineren’. Ook Claude hallucineert nog wel eens. Maar door in de grondwet expliciet een principe op te nemen dat het “Ik weet het niet” moet zeggen als het geen antwoord weet of geen goed onderbouwde inschatting kan maken, verminder je die neiging.
AI zonder vooroordelen?
Een veel gehoorde kritiek op AI-modellen is dat ze vooroordelen hebben, vaak zelfs een specifieke politieke ideologie lijken te promoten. Die kritiek is juist, en is zeker ook op Claude van toepassing. Anthropic heeft een bepaalde keuze van principes gemaakt, en die kun je als vooroordelen beschouwen, ook al zijn ze gebaseerd op de Universele Verklaring van de Rechten van de Mens.
Het verschil met systemen gebaseerd op Reinforcement Learning from Human Feedback is dat bij Claude de principes waarop het AI-model zijn oordelen baseert expliciet zijn. Kritiek op bepaalde vooroordelen is dan ook te pareren door principes uit de grondwet van het AI-model aan te passen, te verwijderen of toe te voegen.
Een AI-grondwet zal dus nooit een onbevooroordeeld AI-model opleveren. Maar wij mensen zijn ook nooit onbevooroordeeld. Wij hangen specifieke waarden aan, door de cultuur waarin we zijn opgegroeid, door de opvoeding die we hebben gekregen, en zoveel meer. Met de aanpak van Anthropic kan ieder dan ook AI-modellen creëren volgens diezelfde waarden. Natuurlijk kan deze aanpak ook misbruikt worden om een AI-model te maken die een grondwet vol racistische, seksistische en kwaadaardige principes volgt. Dat is nu eenmaal de andere kant van de medaille…