De laatste jaren zijn er diverse neurale netwerken ontwikkeld die taal lijken te begrijpen. Op basis van enkele woorden kunnen ze volledige zinnen maken die wel door een mens geschreven zouden kunnen zijn. Hoe werkt dat, en hoe kun je er zelf mee aan de slag? We tonen het aan de hand van BLOOM, een nieuw opensource taalmodel.
 Koen Vervloesem
Koen Vervloesem
Hoe zou je zelf die korte zin “Winter is coming” aanvullen? Als je daarna “This means icy roads, slippery driveways, and chilly evenings to stay in and…” leest, klinkt dit als een heel aannemelijke aanvulling. Opvallend: deze is niet geschreven door een mens, maar door een computer. Of om preciezer te zijn: door het opensource taalmodel BLOOM.
Taalmodel
Eerst even een stapje terug: wat is een taalmodel? Het is eigenlijk een waarschijnlijkheidsverdeling over een reeks woorden. Als je een reeks woorden (een zin dus) aan het taalmodel voert, kent het daar een waarschijnlijkheid aan toe. Een zin met waarschijnlijkheid 0 komt niet in de taal voor. Zo’n taalmodel is een neuraal netwerk dat getraind is op allerlei teksten. In de laatste jaren zijn er heel wat ‘grote taalmodellen’ (large language models of LLM) verschenen (zie het kader Andere grote taalmodellen).
In de praktijk wordt een taalmodel voornamelijk gebruikt om het volgende woord te voorspellen, gegeven enkele woorden die eraan voorafgaan. Zo kun je het taalmodel dus een zin laten aanvullen. Het berekent dan voor alle mogelijke woorden die je kunt invullen de waarschijnlijkheid van de zin tot aan dat woord en kiest het woord die de zin de hoogste waarschijnlijkheid oplevert. Het resultaat? De meest verwachte vervollediging van de zin. En daarom klinkt bovenstaande aanvulling van de woorden “Winter is coming” zo aannemelijk.
BLOOM
Recentelijk is er een nieuw groot taalmodel verschenen, BLOOM. Dit is een acroniem voor BigScience Large Open-science Open-access Multilingual Language Model en het is het resultaat van een wereldwijde samenwerking van meer dan duizend wetenschappers uit meer dan 250 instellingen die als vrijwilligers deelnemen aan het collectief BigScience. Het is gestart door het bedrijf Hugging Face dat een platform voor machine learning aanbiedt, maar ook NVIDIA, Microsoft en de Franse onderzoeksinstelling CNRS (Centre national de la recherche scientifique) dragen bij.
BLOOM is gestart als reactie tegen de grote taalmodellen van Big Tech-bedrijven. Omdat het trainen van zo’n model zoveel processorkracht vereist, zijn bedrijven zoals Google, Microsoft, Meta en OpenAI de enige die daarvoor het geld hebben. Zij kunnen dan ook profiteren van de prestaties van deze taalmodellen en zij bepalen wie toegang tot hun modellen heeft en tegen welke prijs. Daarom is het collectief BigScience met BLOOM gestart om een model te ontwikkelen dat niet alleen door iedereen te gebruiken is, maar waarvan ook de ontwikkeling zelf volledig in het openbaar is gebeurd (https://bigscience.notion.site/BigScience-214dc9a8c1434d7bbcddb391c383922a), zodat iedereen de gemaakte veronderstellingen kan natrekken.
 |
|
BLOOM is getraind op 46 menselijke talen en 13 programmeertalen |
Open model
Hoe BLOOM werkt, verschilt niet zoveel van andere grote taalmodellen. Het gaat om een neuraal netwerk dat getraind is op een grote hoeveelheid tekst. BLOOM heeft 176 miljard parameters en is 3,5 maanden lang getraind op 384 NVIDIA A100 Tensor Core GPU’s met 80 GB RAM van de Jean Zay-supercomputer in Parijs, en dat op een dataset van 1,6 TB (341 miljard woorden).
Een verschil met andere grote taalmodellen is dat BLOOM vanaf het begin ontworpen is om meerdere talen te ondersteunen. Het kan momenteel overweg met 46 menselijke talen (helaas geen Nederlands) en 13 programmeertalen. Een ander belangrijk verschil is dat het hele model open is. Op https://huggingface.co/bigscience/bloom vind je alle mogelijke informatie over het model, inclusief technische specificaties en lessen die de makers geleerd hebben.
Iedereen kan ook het model zelf downloaden, dat overigens 330 GB opslagruimte in beslag neemt. Je hebt wel zware hardware nodig om het zelf te draaien, al wil Hugging Face een API aanbieden waarmee je het voor $40 per uur in de cloud kunt draaien.
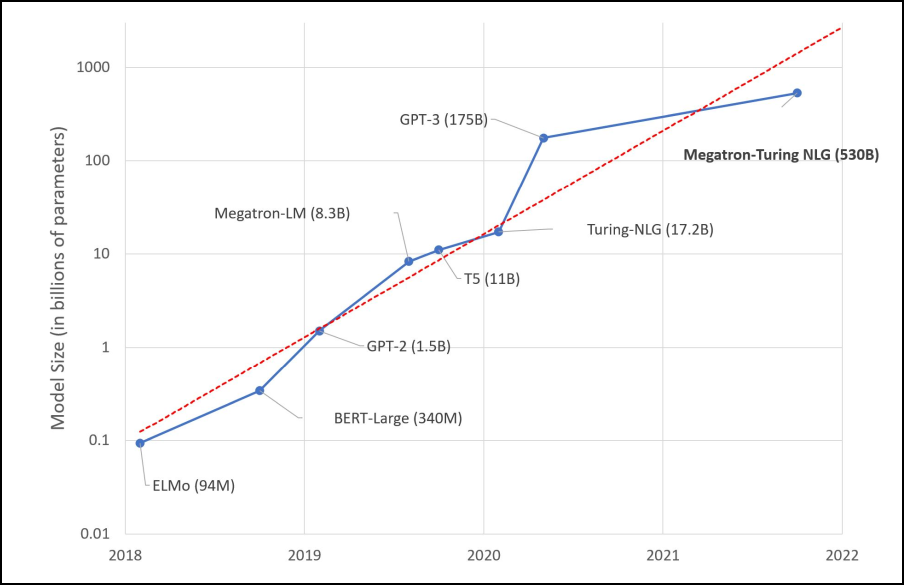
Andere grote taalmodellenDe bekendste grote taalmodellen zijn GPT-2 en GPT-3 (zie Denkwerk in PC-Active 315) van de door Microsoft gesponsorde stichting OpenAI. Vooral rond die laatste (met 175 miljard parameters) ontstond er veel ophef door de heel realistische teksten die het model genereerde, die desondanks vaak onzin bevatten maar heel overtuigend waren. Verder introduceerden Microsoft en NVIDIA het model Megatron-Turing NLG (530 miljard parameters) dat niet alleen tekst kan voorspellen maar ook vragen over een paragraaf kan beantwoorden. Google kon ook niet achterblijven en introduceerde met Pathways Language Model (PaLM) een taalmodel van 540 miljard parameters dat synoniemen kan vinden, oorzaak en gevolg kan onderscheiden, grappen kan uitleggen en filmtitels kan gissen uit een beschrijving met emoji’s. Een ander model van Google, Language Model for Dialogue Applications (LaMDA), kan conversaties voeren, wat Google-ingenieur Blake Lemoine er zelfs van overtuigde dat het model bewustzijn had. En Meta maakte enkele grote taalmodellen beschikbaar onder de naam Open Pre-trained Transformers (OPT), waarvan de grootste 175 miljard parameters heeft. De meeste van deze grote taalmodellen zijn alleen op aanvraag beschikbaar of in een beperkte demo.
Grote taalmodellen worden elk jaar alsmaar groter (bron: Hugging Face) |
Verantwoordelijke AI
Een ander opvallend verschil is de licentie waaronder BLOOM valt: de Responsible AI License (https://huggingface.co/spaces/bigscience/license), afgekort RAIL, ook ontwikkeld door BigScience. De bedoeling van de licentie is vooral om risico’s door onverantwoordelijk gebruik van het model te minimaliseren. Zo mag je volgens de licentie het model niet gebruiken om verifieerbaar foute informatie te genereren met het doel om anderen kwaad te doen. Je mag ook niet nalaten te vermelden dat door het model gegenereerde tekst door een machine is gegenereerd.
Die focus op verantwoordelijk gebruik hadden de onderzoekers al vanaf het begin, met name bij de keuze van de datasets waarop BLOOM getraind werd. Als de datasets eenzijdig zijn, zijn de resultaten immers ook eenzijdig en versterk je vooroordelen. Daarom zocht BigScience speciaal datasets bij elkaar die tevoren nog niet online te vinden waren, onder andere in enkele kleine Afrikaanse talen.
Wat kan BLOOM zoal?
BLOOM is getraind als een voorspeller van het volgende woord op basis van een reeks voorgaande woorden. Dus je geeft het een aantal woorden, zoals “Winter is coming”, en BLOOM berekent dan de grootste kanshebbers om hierna te komen. Het resultaat is een nieuw woord, en dat woord voeg je dan aan de vorige woorden toe. De volledige reeks, “Winter is coming. This” geef je dan weer aan het model en het berekent nu weer een nieuw woord dat hier waarschijnlijk achter komt. En zo vervolledigt het model woord per woord je zin. Overigens krijg je niet elke keer hetzelfde resultaat, omdat het een probabilistisch model is.
 |
|
BLOOM kan ook taken uitvoeren zoals onregelmatige werkwoorden vervoegen |
Je kunt dit zelf uitproberen op https://
huggingface.co/
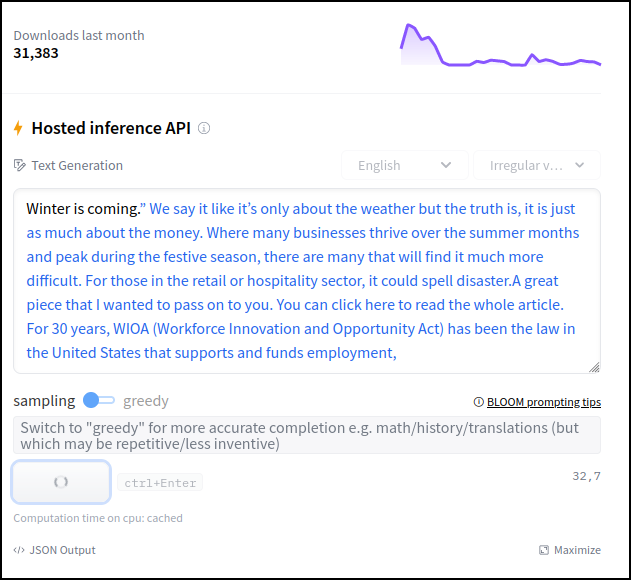
bigscience/bloom in het veld onder Hosted inference API rechts. Hier draait BLOOM op een server waartoe iedereen als demo toegang krijgt. Vul enkele Engelstalige woorden in en klik eronder op Compute. Beschouw BLOOM niet als een chatbot, maar een vervollediger. Vul dus gewoon enkele woorden in alsof je aan een onderwerp van een e-mail of aan een artikel begint. Het is ideaal als je om inspiratie voor een tekst verlegen zit.
Zoals alle grote taalmodellen kun je met BLOOM ook veel meer dan waarvoor het expliciet is getraind. Je kunt immers allerlei andere taken in de vorm van tekstvervolledigingen zetten. Op de website van BLOOM krijg je al een voorproefje hiervan. Klik je onder Hosted inference API op English, dan kun je rechts daarvan in het uitklapmenu enkele voorbeelden opvragen.
 |
|
Na een tijdje maakt BLOOM vaak bizarre wendingen in zijn verhaal |
Beperkingen
Als je in de demo op Compute blijft klikken om een vervollediging nog verder te vervolledigen, zul je telkens na enkele klikken al merken dat het niet loopt zoals verwacht. BLOOM begint dan plots over iets heel anders en voegt zinnen toe die helemaal niets te maken hebben met die daarvoor. De interne consistentie van langere teksten is vaak zoek.
Op andere momenten lijkt er in het begin een verrassend consistente lijn in de gedachtegang van een door BLOOM geschreven tekst te zitten, maar wordt het verhaal plots afgebroken. Je krijgt dan een herhaling van het begin maar dan in andere woorden. Die beperkingen zijn te wijten aan het feit dat BLOOM helemaal niet begrijpt waar het om gaat. Uiteindelijk past het model gewoon statistiek toe.
Kan een groot taalmodel redeneren?
Sommigen beweren nochtans dat grote taalmodellen de mogelijkheid hebben om te redeneren. Maar onderzoekers van Arizona State University hebben dit in een studie (https://arxiv.org/abs/2206.10498) getest met GPT-3. Uit hun onderzoek blijkt dat GPT-3 wel slaagt volgens veel benchmarks, maar dat deze te eenvoudig zijn en GPT-3 dus kan valsspelen met statistische trucs.
Vaak gaat het om redeneringen met één of twee stappen, waar grote taalmodellen nog goed in scoren omdat ze dan kunnen teren op hun vermogen op patroonherkenning. Het model heeft dan waarschijnlijk gewoon een patroon in zijn vele trainingsdata gezien dat het dan succesvol generaliseert. Oppervlakkig gezien lijkt het dan alsof het kan redeneren. Maar dit vermogen is niets meer waard als je redeneringen met meer stappen vraagt, als het echt om plannen gaat. Dat bleek dan ook uit het onderzoek. Voor toekomstig onderzoek naar het redeneervermogen van grote taalmodellen kunnen de tests die de onderzoekers publiceerden nuttig zijn als benchmark.
