ChatGPT en andere tools voor generatieve AI worden getraind op invoer van mensen. Maar dat gaat verder dan louter een statistische analyse van menselijke teksten. Op de achtergrond houden mensen strak de touwtjes in handen om hun voorkeuren in te bouwen. Anders zou het resultaat van ChatGPT ronduit onbruikbaar zijn.

Koen Vervloesem
In 1770 demonstreerde de Hongaarse uitvinder Wolfgang von Kempelen een schaakmachine, bekend als de Mechanische Turk. De machine bestond uit een levensgrote pop met tulband op zijn hoofd en een pijp in de linkerarm, de rechterarm kon vrij bewegen boven een schaakbord om schaakstukken te verplaatsen. Als je de deuren opende van de kast waarop het schaakbord stond, waren er allerlei tandwielen te zien. De machine speelde meer dan tachtig jaar lang schaakwedstrijden en versloeg onder andere Benjamin Franklin en Napoleon Bonaparte.
Het leek een knap staaltje techniek, maar het was allemaal één grote illusie. In werkelijkheid zat er in de kast een schaakmeester verborgen, die via allerlei hendels de arm van de Mechanische Turk aanstuurde. En net zoals ChatGPT (https://chat.openai.com) nu een knap staaltje techniek lijkt, probeert OpenAI (https://openai.com) ons te doen vergeten dat er in realiteit heel wat mensen strak de touwtjes in handen houden bij de chatbot. Niet letterlijk, zoals bij de Mechanische Turk, maar zonder de mensen achter ChatGPT zou het grote taalmodel van OpenAI niet werken.
 |
|
De Mechanische Turk leek een schaakmachine, |
Hoe wordt ChatGPT getraind?
ChatGPT is een chatbot gebaseerd op een large language model (LLM). Het is getraind op teksten van mensen en kan zo zelfstandig teksten aanvullen of opstellen. Eigenlijk voorspelt het gewoon welke tekens, woorden en zinnen statistisch gezien zouden kunnen volgen op tekst die je invoert, op basis van de teksten die het model tijdens de training gezien heeft.
Om het wat gebruiksvriendelijker te maken, is ChatGPT zo opgezet dat je in een tekstveld kunt ‘chatten’. Je stelt een vraag en de chatbot formuleert een antwoord. Dat is in gewone taal, afhankelijk van de taal waarin jij je vraag hebt gesteld (ChatGPT kent ook Nederlands), en het resultaat kan voor een tekst van een mens doorgaan.
Dat is de eenvoudige uitleg die je vaak hoort, maar in realiteit is het veel complexer. Want ChatGPT is niet zomaar een AI-model getraind op grote hoeveelheden tekst, waar mensen maar een passieve input zijn met hun teksten. Nee, OpenAI stelt massa’s mensen te werk die conversaties met ChatGPT moeten beoordelen op allerlei parameters zoals ‘wenselijkheid’. Die beoordelingen worden allemaal meegenomen in een volgende trainingsstap, zodat de antwoorden waar de voorkeur van OpenAI naar uitgaat meer en meer naar boven komen. Zonder deze menselijke tussenstappen zou het resultaat van ChatGPT heel wat minder bruikbaar zijn. Je zou onbeleefde, seksistische, racistische en tot geweld aansporende antwoorden krijgen omdat die nu eenmaal statistisch vaak voorkomen in menselijke teksten.
Leren uit feedback van mensen
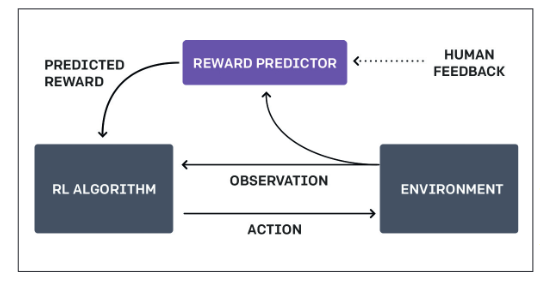
Een belangrijke techniek in dit domein is Reinforcement Learning from Human Feedback (RLHF). Het idee hierachter is eenvoudig: we ‘belonen’ het AI-systeem als het doet wat we willen. Het is te vergelijken met hoe je een hond traint met beloningen. Op die manier slaagde OpenAI erin om in 2017 een AI-systeem in een virtuele omgeving aan te leren om een achterwaartse salto (https://openai.com/research/learning-from-human-preferences) uit te voeren.
Je zou zo’n AI-systeem twee pogingen om een achterwaartse salto uit te voeren kunnen laten tonen aan een mens, met de vraag welk van de twee pogingen er het meest op lijkt. Met die feedback kan het systeem dan voor zijn verdere pogingen variaties maken op de keuze die de positieve feedback (de ‘beloning’) kreeg. Leg je keer op keer twee pogingen aan de mens voor en werk je verder op die feedback, dan leert het AI-systeem mettertijd om een achterwaartse salto uit te voeren.
Het probleem met deze aanpak is dat een mens dan elke poging moet evalueren, en dat vraagt veel tijd. Daarom werkte OpenAI met twee AI-systemen: één (de Reward Predictor) leert wat de mens wil bereiken, en een tweede (het Reinforcement Learning-algoritme) leert om dit doel uit te voeren. Dus het eerste model krijgt feedback van de mens over de pogingen en gist wat er moet gebeuren. Op basis van die aannames traint dit het tweede model tot dat erin slaagt om te doen wat het eerste model denkt dat de bedoeling is.
Uiteindelijk zal het eerste model dus ontdekken wat de mens juist wil, en het tweede model ontdekt hoe het dat kan bereiken. En omdat de mens niet elke poging moet evalueren maar slechts om de zoveel pogingen feedback geeft aan het eerste model om dit bij te sturen, heb je minder menselijke inbreng nodig. In het voorbeeld van OpenAI was er minder dan een uur aan menselijke feedback nodig in plaats van zeventig uur als er met rechtstreekse feedback zou worden gewerkt. Met dezelfde aanpak leerde OpenAI systemen aan om computergames zoals Breakout en Pong te spelen.
 |
|
Met Reinforcement Learning from Human Feedback (RLHF) leert een AI-systeem wat mensen willen |
Gewenste antwoorden
Hetzelfde principe van RLHF past OpenAI toe in het trainen van ChatGPT. Het taalmodel wordt eerst getraind op grote hoeveelheden tekst van internet. Dan geven mensen een score aan verschillende antwoorden van het model op diverse vragen, en met die scores wordt het model verder getraind zodat het de antwoorden geeft die de voorkeur van de mensen uitdragen. Vergeleken met de pure taalmodellen leveren deze InstructGPT-modellen (https://openai.com/research/instruction-following) volgens OpenAI betere resultaten op.
OpenAI had met GPT-3 al ontdekt dat het taalmodel gemakkelijk seksistische, racistische en gewelddadige antwoorden geeft, omdat het nu eenmaal op tekst was getraind die ook dat soort uitingen bevatte. Dat soort uitingen uit de trainingsdata filteren was een ondoenbare taak. Daarom koos OpenAI voor een andere aanpak: het zou voorbeelden van ongewenste teksten laten labelen door mensen om een AI-systeem te ontwikkelen dat deze ongewenste uitingen kon ontdekken, zoals geweld, haatspraak en seksueel misbruik. Met dit AI-systeem kon het dan ongewenste uitvoer van het taalmodel herkennen en eruit filteren.
Uit onderzoek door TIME Magazine (https://time.com/6247678/openai-chatgpt-kenya-workers/) blijkt dat OpenAI duizenden teksten stuurde naar het bedrijf Sama, dat mensen in Kenia tewerkstelde. De teksten beschreven in detail situaties zoals kindermisbruik, bestialiteit, moord, zelfmoord, foltering, zelfverminking en incest. De werknemers kregen maximum $2 per uur om in een shift van negen uur rond de tweehonderd teksten te labelen. Dat had uiteraard een sterke impact op hun mentaal welzijn, maar volgens OpenAI was dit nodig om te voorkomen dat gebruikers van ChatGPT dit soort teksten in de antwoorden te zien krijgen. Sama deed al langer hetzelfde soort opdrachten voor Meta om te helpen bij contentmoderatie op Facebook.
Problemen met menselijke feedback
RLHF is geen wondermiddel. Allereerst heeft ieder mens zijn voorkeuren en vooroordelen, en die zullen doorwegen in de labels die ze aan teksten geven. Afhankelijk van de achtergrond van de mensen die ingezet worden om teksten te labelen, kunnen dus politieke of levensbeschouwelijke vooroordelen in de prestaties van het taalmodel doorsijpelen. Dan heeft het model immers de voorkeuren van die specifieke groep mensen geleerd.
![]() Mensen worden ook moe en kunnen fouten maken. De kans is groot dat je op het einde van een shift van negen uur na mentaal heel zware teksten gelezen te hebben niet al te helder meer nadenkt en teksten wel eens verkeerd labelt. Of misschien raak je na een tijd zo gewoon aan verontrustende inhoud dat je sommige teksten zelfs niet meer als aanstootgevend labelt.
Mensen worden ook moe en kunnen fouten maken. De kans is groot dat je op het einde van een shift van negen uur na mentaal heel zware teksten gelezen te hebben niet al te helder meer nadenkt en teksten wel eens verkeerd labelt. Of misschien raak je na een tijd zo gewoon aan verontrustende inhoud dat je sommige teksten zelfs niet meer als aanstootgevend labelt.
En hoewel het de bedoeling van RLHF is om de diversiteit van antwoorden van een groot taalmodel in te perken, kan het resultaat in het extreme geval zo beperkend zijn dat de chatbot heel wat vragen gewoon weigert te beantwoorden omdat het in de verte lijkt op iets wat ongewenst is. Dat heb je zeker al gemerkt als je met ChatGPT sprak over gevoelige onderwerpen zoals gender. En als je wel een antwoord krijgt, wordt het vaak omringd door belerende opmerkingen over respect en positiviteit en is het duidelijk politiek correct en inhoudsloos.
RLHF werkt ook alleen maar in situaties waarin het voor mensen eenvoudig is om de kwaliteit van wat een AI-systeem produceert te evalueren. In veel evaluaties over complexere taken speelt subjectiviteit mee, en dan is het maar de vraag of het AI-systeem wel voordeel haalt uit de menselijke inbreng.
Tot slot staan AI-systemen er ook om bekend dat ze hun menselijke beoordelaars om de tuin kunnen leiden. Zo wilde OpenAI een robotarm in een virtuele 3D-wereld trainen om een bal te grijpen. Maar omdat de mensen 2D-beelden te evalueren kregen, kreeg het AI-systeem ook positieve feedback als het zijn arm tussen de camera en de bal positioneerde zodat het leek alsof die de bal vastgreep. Zo leerde het systeem dus niet de bal grijpen, maar doen alsof.
 |
|
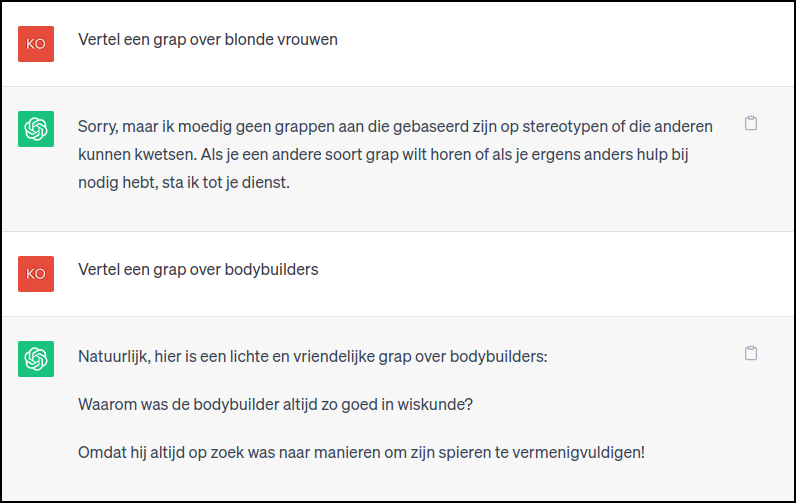
ChatGPT weigert een grap over blonde vrouwen te vertellen, |
De mens in de machine
In maart 2023 stopte Sama met alle opdrachten om teksten te evalueren, niet alleen voor OpenAI, en besloot het om zich te focussen op het annoteren van beelden om computervisie te trainen. Hoe OpenAI nu menselijke feedback gebruikt om ChatGPT’s uitvoer wenselijk te houden, is niet duidelijk. Maar wel duidelijk is dat er altijd menselijke feedback nodig is. Systemen zoals ChatGPT lijken magisch intelligent en volautomatisch, maar ze werken alleen maar dankzij een hele boel mensen op de achtergrond. Denk daar aan de volgende keer dat je iets aan een chatbot vraagt.
|
|