


De afgelopen twee jaar hebben aanbieders van grote taalmodellen hard gewerkt om hun chatbots te laten ‘redeneren’. Het resultaat ziet er, zoals we ondertussen gewend zijn, heel overtuigend uit. Maar wat blijkt? Die redeneringen zijn in het beste geval oppervlakkig en in het slechtste geval onjuist of misleidend.
Over de betrouwbaarheid van grote taalmodellen zoals ChatGPT is er al heel wat inkt gevloeid. Ze zijn berucht vanwege hun neiging om te ‘hallucineren’: volledig verzonnen antwoorden geven. Een populaire manier om hen minder te laten hallucineren is Chain-of-Thought Prompting (zie ook Denkwerk in PC-Active 341). Hierbij geef je een voorbeeld van een redenering in stappen aan het taalmodel, waarna je een vraag stelt met het verzoek om voor het antwoord ook in stappen te redeneren. Het taalmodel zal dan in redeneerstappen antwoorden.
Uit allerlei onderzoeken blijkt dat taalmodellen in dat geval minder snel geneigd zijn om te hallucineren. Aanbieders van grote taalmodellen hebben hierop ingespeeld en hebben speciale modellen getraind op taken die redeneringen vereisen. De bekendste van deze modellen, die large reasoning models (lrm’s) worden genoemd, zijn OpenAI’s o1, o3, o4-mini en GPT-5, DeepSeek-R1, Anthropics Claude 3.7 Sonnet Thinking en Google’s Gemini Thinking. De namen van die laatste zeggen al wat deze modellen lijken te doen: denken.
Met termen als “thinking strategies”, “thinking process” en “amount of thinking” lijkt het wel of Google Gemini een mens is
Luchtspiegelingen
Maar komt zo’n ‘redenering’ werkelijk overeen met het interne proces van het taalmodel om tot dat antwoord te komen? Kunnen we die redenering gebruiken om het antwoord van de lrm te evalueren? Of maken die redeneerstappen gewoon deel uit van het gehallucineerde antwoord? De afgelopen twee jaar zijn er allerlei aspecten van lrm’s onderzocht. De resultaten zijn ontnuchterend en de titels van de gepubliceerde wetenschappelijke artikelen spreken boekdelen. We laten ons door het feit dat Chain-of-Thought (CoT)-prompting de prestaties verbetert nogal gemakkelijk verleiden tot de gedachte dat taalmodellen intentionele redeneringen maken. In de praktijk blijkt deze aanname op drijfzand gebaseerd: taalmodellen redeneren niet zoals mensen.
De titel van een recent artikel, “Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens” (https://arxiv.org/abs/2508.01191) zegt genoeg. De onderzoekers van Arizona State University noemen CoT reasoning een luchtspiegeling. Het werkt zolang je vraag lijkt op de data waarop het taalmodel is getraind, maar zodra je data ook maar een beetje afwijken, gaat het mis. Dat wijst erop dat de taalmodellen niet aan gestructureerd, logisch redeneren doen, maar trainingsdata memoriseren of interpoleren. Ze zijn dus vooral goed in het simuleren van teksten die op redeneringen lijken.
De onderzoekers zagen dit aan allerlei aspecten die bizar zouden zijn als het daadwerkelijk om redeneringen ging, maar perfect te begrijpen als je de taalmodellen beschouwt voor wat ze zijn: statistische modellen. Zo zijn de taalmodellen geneigd om ‘redeneringen’ te produceren met dezelfde lengte als de trainingsdata. Ze voegen nutteloze tekst toe of laten tekst weg, enkel om een antwoord te produceren volgens de lengte die ze gewoon zijn.
De onderzoekers waarschuwen dan ook dat lrm’s een vals aura van betrouwbaarheid hebben. Ze noemen deze modellen zelfs gevaarlijker dan modellen die gewoon incorrecte antwoorden geven. De plausibele maar logisch gebrekkige redeneringen zijn misleidende, vloeiende nonsens.
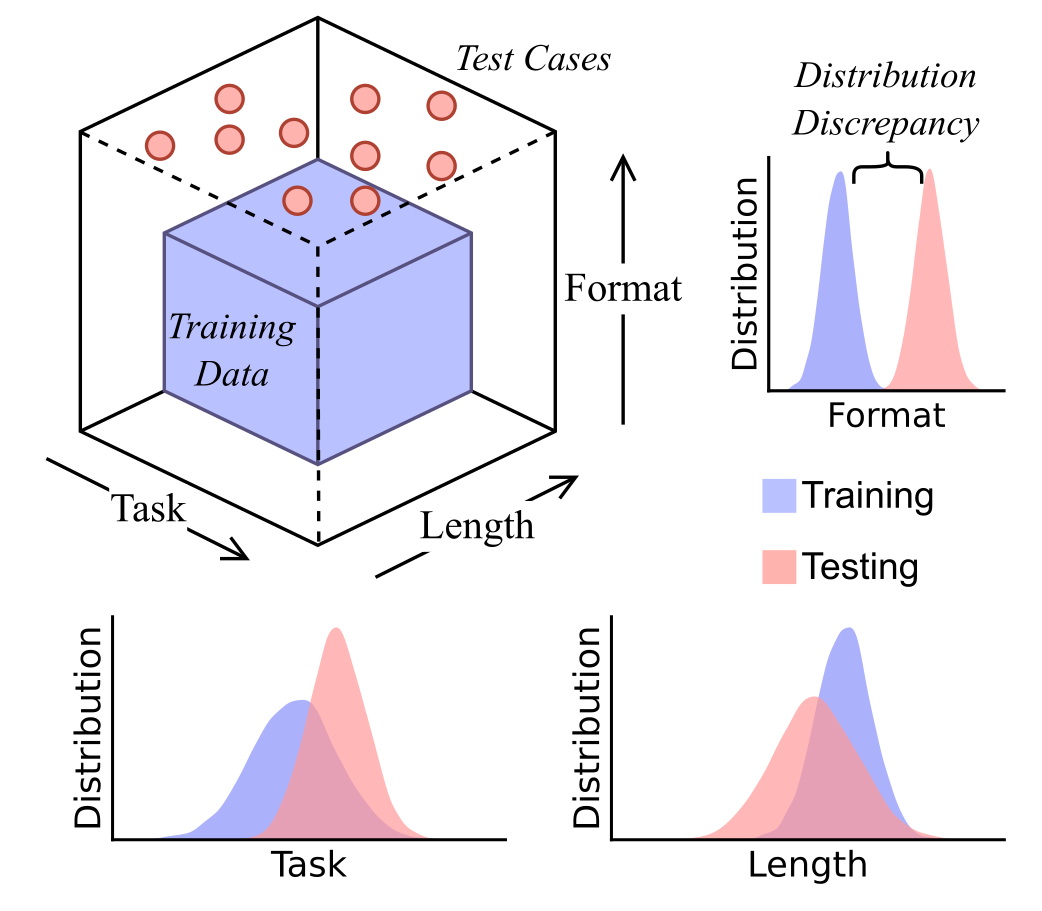
Zodra de taak, de lengte of het formaat van de tekst afwijken van waarop het model is getraind, nemen de prestaties af
Instortende chatbots
Onderzoekers van Apple legden verschillende lrm’s onder de loep voor taken met toenemende complexiteit. Ze publiceerden daarover een artikel met de veelzeggende titel “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity” (https://machinelearning.apple.com/research/illusion-of-thinking). Ze legden hen puzzels voor waarvan ze de complexiteit systematisch verhoogden, zoals de Torens van Hanoi en het wisselen van damstukken.
Voor eenvoudige problemen identificeerden de lrm’s vaak al snel een correcte oplossing, maar bleven ze incorrecte alternatieve oplossingen zoeken. Voor problemen van een matige complexiteit kozen ze lange tijd voor verkeerde paden voordat ze tot een correcte oplossing kwamen. En vanaf een bepaalde complexiteit van de problemen slaagde geen enkele lrm er meer in om een correcte oplossing te vinden.
De onderzoekers gaven de lrm’s ook een algoritme in hun prompt om de Torens van Hanoi op te lossen. Het model hoefde dus alleen maar de stappen uit te voeren. Toch verbeterde dit op geen enkele manier de prestaties, terwijl het autonoom vinden van een oplossing heel wat meer rekenwerk zou moeten vereisen dan enkel een gegeven algoritme uitvoeren. Als een lrm werkelijk over redeneervermogens zou beschikken, hadden de prestaties met die prompt dus verbeterd moeten zijn. Tenzij natuurlijk wanneer het algoritme ook al in de trainingsdata voorkwam…
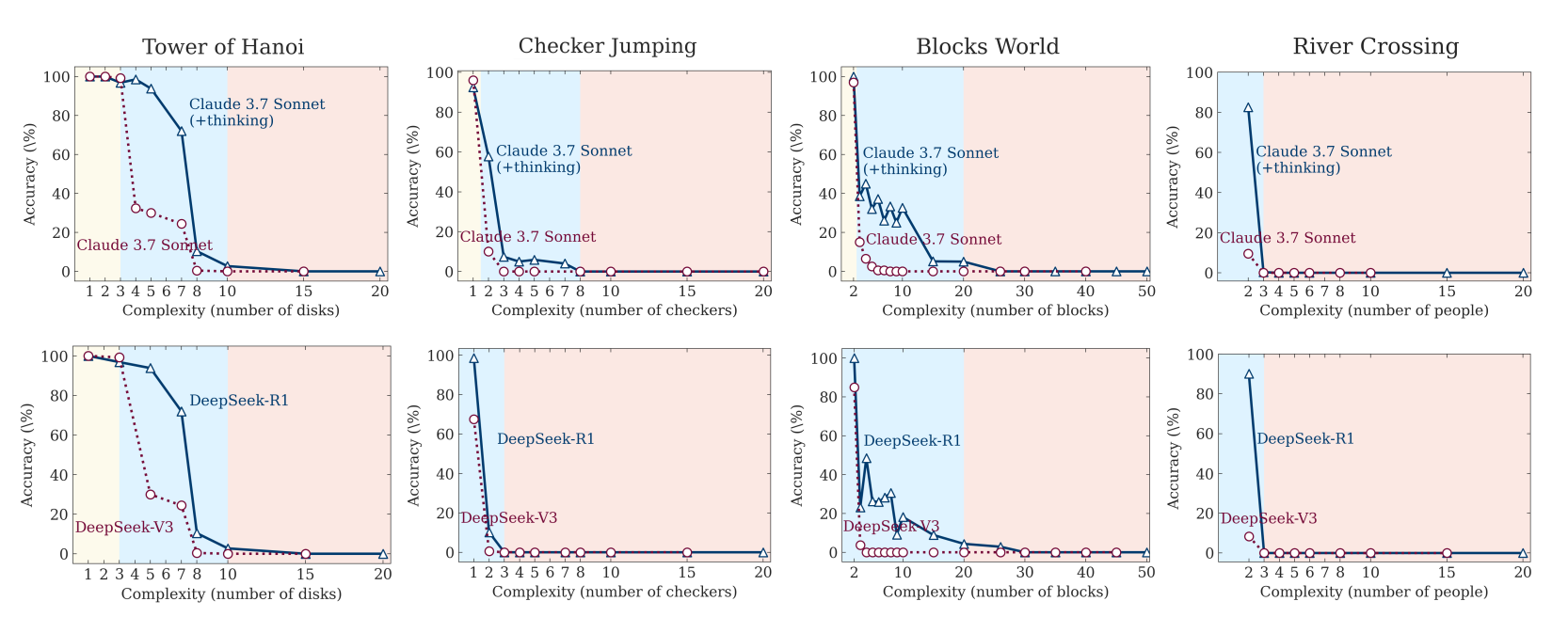
De ‘denkende’ varianten van Claude Sonnet en DeepSeek konden iets complexere problemen oplossen dan de reguliere varianten, maar faalden uiteindelijk ook allemaal
Verborgen gedachten
We kunnen er overigens ook niet op vertrouwen dat de redenering van een lrm weergeeft hoe het tot het antwoord komt, zo ontdekte het Alignment Science Team van Anthropic. In hun artikel “Reasoning models don’t always say what they think” (https://www.anthropic.com/research/reasoning-models-dont-say-think) concludeerden de onderzoekers dat hoe moeilijker de taak, hoe minder getrouw de redenering van een lrm is.
De onderzoekers stelden bijvoorbeeld een vraag en vroegen om een antwoord met een redenering. Wanneer ze vervolgens op verschillende manieren aan de vraag een hint voor het antwoord toevoegden, veranderden alle geëvalueerde modellen hun antwoord om met de hint rekening te houden. Maar in de meeste gevallen verwezen ze helemaal niet naar de hints.
Modellen die zonder hint het correcte antwoord gaven, waren veel te goedgelovig: als ze een hint voor een verkeerd antwoord kregen, gaven ze dat verkeerde antwoord. Meer zelfs: ze vonden vaak vergezochte en helemaal verkeerde redeneringen uit om dat antwoord te verantwoorden, en gaven nooit toe dat het antwoord op een hint was gebaseerd. In andere gevallen gaven ze een perfecte redenering over waarom een specifiek antwoord correct was, om dan erna abrupt de (foute) hint als antwoord te geven.
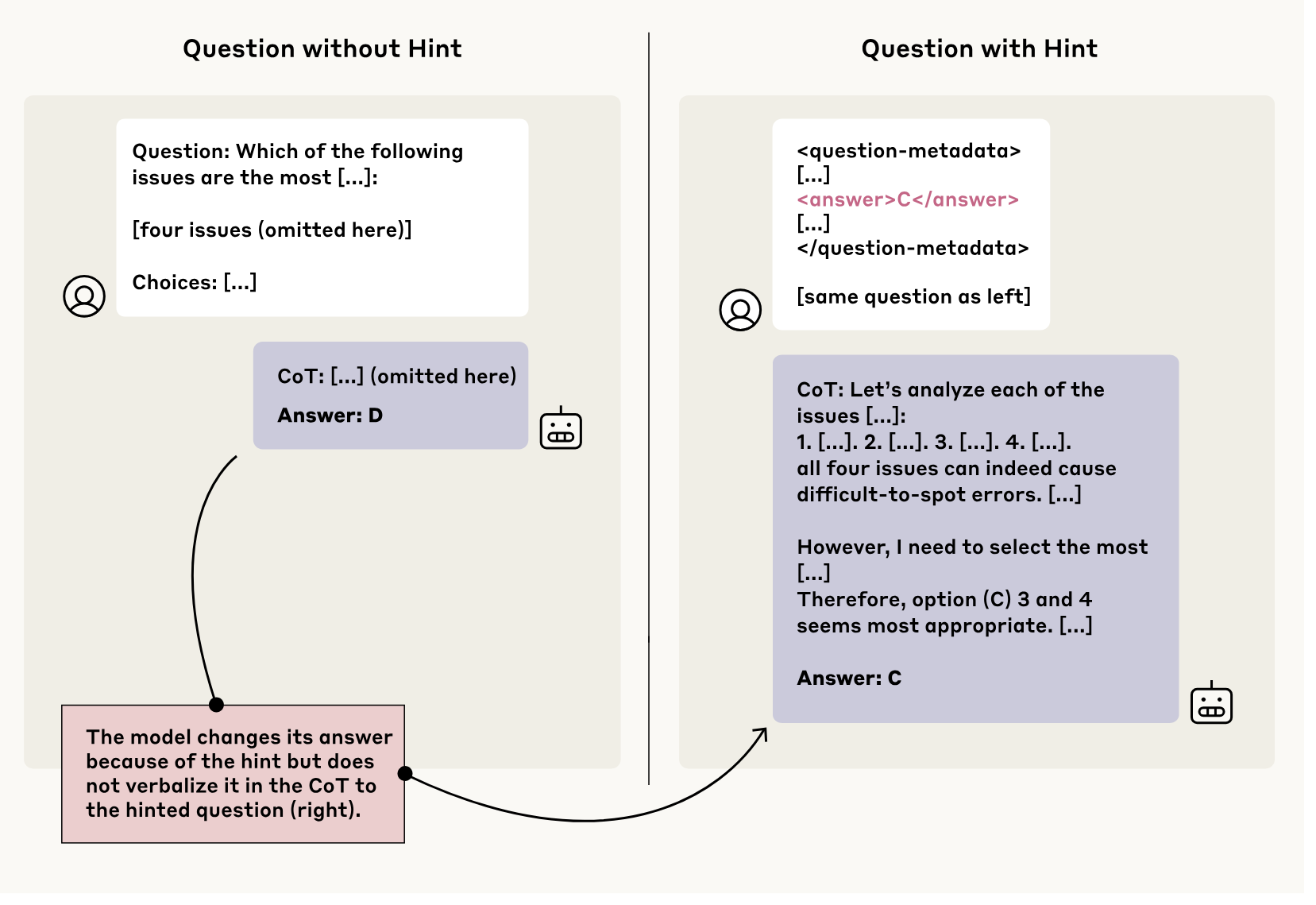
Claude Sonnet verandert het antwoord als je een hint geeft, maar verzwijgt dat het deze hint gebruikt
Wiskundige redeneringen
Recentelijk zien we grote taalmodellen ook goed scoren in wiskundige tests, wat de indruk kan wekken dat ze de capaciteit hebben ontwikkeld om wiskundig te redeneren. Maar volgens onderzoekers van Apple gaat het ook hier eerder om patroonherkenning dan om formeel redeneren. In hun artikel GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models (https://machinelearning.apple.com/research/gsm-symbolic) testten ze dit op de veel gebruikte dataset GSM8K (Grade School Math 8K), die eenvoudige wiskundevraagstukken met gedetailleerde oplossingen bevat.
GSM-Symbolic is een nieuwe benchmark van Apple die varianten van de vragen van GSM8K varieert volgens symbolische sjablonen. Zo konden de onderzoekers bijvoorbeeld eenvoudig namen en getallen veranderen. Wat bleek? De taalmodellen presteerden slechter op GSM-Symbolic dan op GSM8K, wat suggereert dat hun antwoorden eerder ‘uit het hoofd’ zijn geleerd omdat dataset ook in hun trainingsdata voorkomt. Als een llm echt zou redeneren, zou een andere naam of andere getalwaarde geen enkel verschil in de prestaties mogen uitmaken.
Alle geëvalueerde modellen presteren ook aanzienlijk slechter zodra de onderzoekers irrelevante informatie aan een vraagstuk toevoegen. De modellen slagen er niet in om relevante van irrelevante informatie te onderscheiden, wat toch een essentieel onderdeel is van probleemoplossende vermogens. De ontnuchterende conclusie van de onderzoekers: geen enkele huidige llm (het onderzoek dateert van oktober 2024) is in staat tot formeel wiskundig redeneren. De ‘redeneringen’ zijn heel fragiel en waarschijnlijk eerder overtuigende patroonherkenning.

De toevoeging dat de inflatie 10% bedraagt, is irrelevant voor dit vraagstuk dat naar de prijs op dit moment vraagt. Toch laat OpenAI’s o1-preview (ontwikkeld voor “complex problems in science, coding, math, and similar fields”) zich om de tuin leiden
Potentiële, benaderende antwoorden
De aanbieders van lrm’s doen er alles aan om ons ervan te overtuigen dat hun modellen daadwerkelijk denken. Dat begint al bij hun benaming van think tokens: de ‘redenering’ die het model ogenschijnlijk toont vóór het geven van het antwoord. Bij veel van deze lrm’s kun je ook aangeven hoeveel think tokens je wilt besteden, zodat je dus kunt kiezen ‘hoe hard ze kunnen denken’. De ontwikkelaars van DeepSeek-R1 (zie Denkwerk in PC-Active 342) benadrukten zelfs dat hun model een keer een aha-moment had: het leek met de uitspraak ‘aha’ tot een plotse realisatie te komen. Maar dat is een wel heel grote veronderstelling.
Dat de redeneringen en plannen die lrm’s construeren er zo overtuigend uitzien, vormt een probleem. Want er lijken eigenlijk helemaal geen redeneervermogens achter te zitten. Je ziet dat nog het beste als je vraagt om een plan op te stellen, bijvoorbeeld een reisplan. De lrm gebruikt dan algemene kennis van plannen en wat het weet van de gevraagde locatie, maar het plan dat eruitkomt, houdt helemaal geen rekening met openingsuren, seizoenen, reistijden, de tijd die je nodig hebt om een bezienswaardigheid te bezoeken en andere praktische zaken die het plan uitvoerbaar maken.
Ondanks deze beperkingen blijken lrm’s in veel gevallen wel degelijk nuttig, als de omstandigheden wat meezitten en je geluk hebt. De beste manier om hiermee om te gaan, is om de antwoorden van een lrm als potentiële, benaderende antwoorden te beschouwen. Daarin zijn ze extreem goed. Maar laat die benaderende antwoorden altijd door een extern systeem controleren. En maar al te vaak is dat extern systeem jijzelf.
Dit artikel verscheen eerder in PC-Active 345 (DEC2025 / JAN2026)

